Step 5: Update the Siddhi Application¶
A Siddhi application can be easily extended to consume messages from more sources, to carry out more processing activities for data or to publish data to more destinations. For this example, consider a scenario where you also need to filter out the production data of eclairs and publish it to a Kafka topic so that applications that cannot read streaming data can have access to it. This involves extending the SweetFactoryApp Siddhi application to include Kafka in the streaming flow so that it functions as shown in the diagram below.
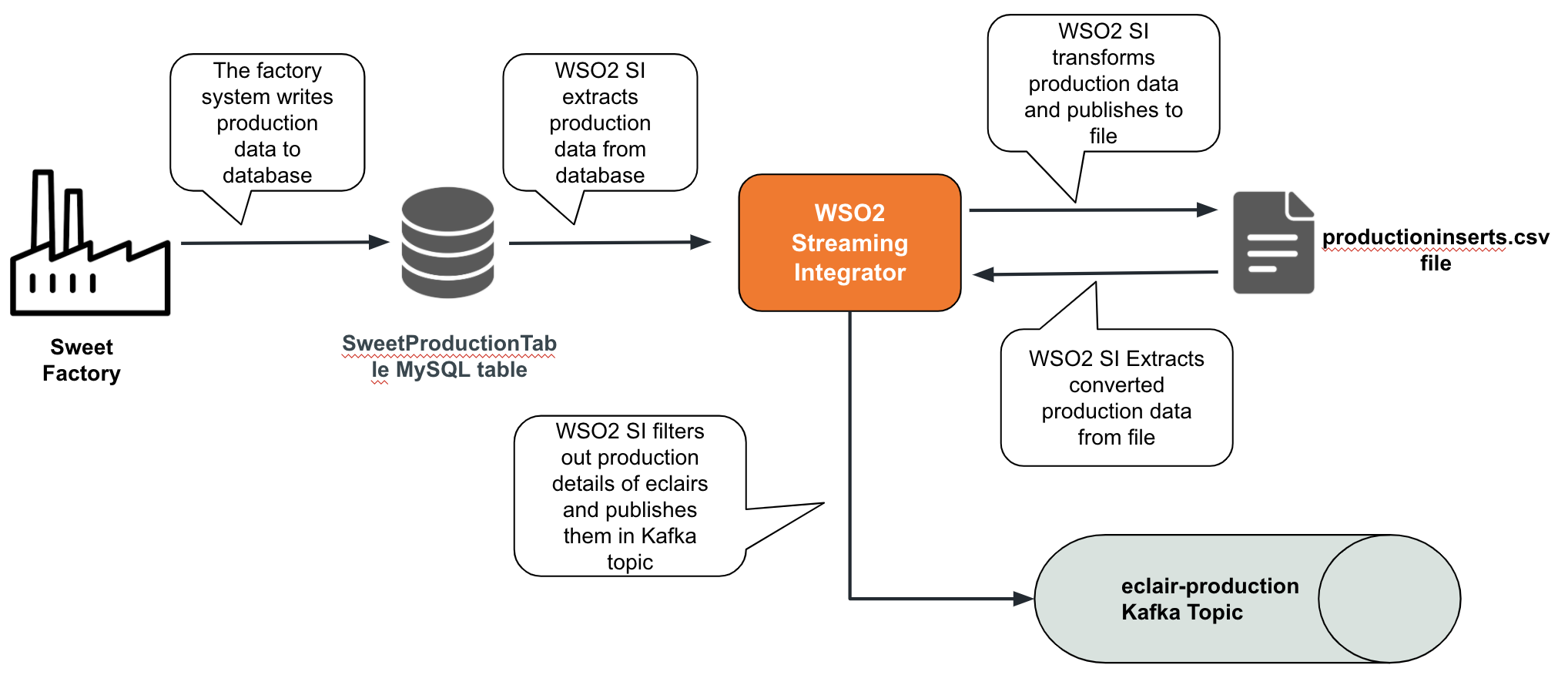
To update the SweetFactoryApp Siddhi application so that it functions as described, follow the steps below:
-
Start and access Streaming Integrator Tooling. Click the File Explorer icon in the side panel and then click SweetFactoryApp.siddhi to open the Siddhi application that you already created and saved.
-
Define another stream to which you can direct the filtered events you need to publish in a the Kafka topic.
define stream FilterStream (name string,amount double); -
To publish the events filtered into the
PublishFilteredDataStreamstream, connect a source of thekafatype to it as shown below.@sink(type = 'kafka', bootstrap.servers = "localhost:9092", topic = "eclair-production", is.binary.message = "false", partition.no = "0", @map(type = 'json')) define stream PublishFilteredDataStream (name string,amount double);
The above sink annotation publishes all the events received into the PublishFilteredDataStream stream into a topic named eclair-production in json format.
-
Let's create another stream to read from the
/Users/foo/productioninserts.csvfile to which you have been publishing data.Tip
Alternatively, you can write the query to read from one of the existing streams. However, in this example, let's create a new stream to understand how ESB Streaming Integrator reads data from files.
@source(type='file', mode='LINE', file.uri='file:/Users/foo/productioninserts.csv', tailing='true', @map(type='csv')) define stream FilterStream (name string,amount double);Here, you are configuring the file to be read line by line in the tailing mode. Therefore, any new row added to the file is captured as an event in the
FilterStreamstream as and when it is added. -
Now let's add the query to filter the required information and publish it.
from FilterStream [name=='ECLAIRS'] select * group by name insert into PublishFilteredDataStream;In the
fromclause,[name=='ECLAIRS']filters all production runs where the name of the sweet produced isEclairs. Then all the filtered events are inserted into thePublishFilteredDataStreamstream so that they can be published in theeclair_productionKafka topic. -
Save your changes.
The completed Siddhi application looks as follows:
@App:name('SweetFactoryApp') @source(type='cdc',url = "jdbc:mysql://localhost:3306/production",username = "wso2si",password = "wso2",table.name = "SweetProductionTable",operation = "insert", @map(type='keyvalue')) define stream InsertSweetProductionStream (name string,amount double); @source(type='file', mode='LINE', file.uri='file:/Users/foo/productioninserts.csv', tailing='true', @map(type='csv')) define stream FilterStream (name string,amount double); @sink(type='file',file.uri = "/Users/foo/productioninserts.csv", @map(type='csv')) define stream ProductionUpdatesStream (name string,amount double); @sink(type = 'kafka', bootstrap.servers = "localhost:9092", topic = "eclair_production", is.binary.message = "false", partition.no = "0", @map(type = 'json')) define stream PublishFilteredDataStream (name string,amount double); @info(name='query1') from InsertSweetProductionStream select str:upper(name) as name, amount group by name insert into ProductionUpdatesStream; from FilterStream [name=='ECLAIRS'] select * group by name insert into PublishFilteredDataStream; -
Deploy the updated
SweetFactoryAppSiddhi application as you previously did in Step 3: Deploy the Siddhi Application. -
The
kafkaextension is not shipped with the Streaming Integrator Server by default. Therefore, install it via the Extension Installer Tool. You can do this by starting the Streaming Integrator server and then issuing the appropriate command (based on your operating system) from the<SI_HOME>/bindirectory.- For Linux:
./extension-installer.sh install kafka - For Windows:
extension-installer.bat install kafka
- For Linux:
-
To test the Siddhi application after the update, insert records into the
productiondatabase as follows.insert into SweetProductionTable values('eclairs',100.0);insert into SweetProductionTable values('eclairs',60.0);insert into SweetProductionTable values('toffee',40.0); -
To check the messages in the
eclair_productiontopic, navigate to the<KAFKA_HOME>directory and issue the following command:bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic eclair-production --from-beginningYou can see the following messages in the Kafka Consumer log.
{"event":{"name":"ECLAIRS","amount":100.0}} {"event":{"name":"ECLAIRS","amount":60.0}}
Note that the third record you inserted does not appear in the Kafka consumer log because the value for the name field is not ECLAIRS and therefore, it is filtered out.
What's Next?
Next, you can configure ESB Streaming Integrator to handle errors that can occur in the Streaming Integration flow of the SweetFactoryApp Siddhi application. To do this, proceed to Step 7: Handle Errors.