Extracting Data from Static Sources in Real Time¶
ESB Streaming Integrator can extract data from static sources such as databases, files and cloud storages in real-tme.
Consuming data from RDBMS databases¶
A database table is a stored collection of records of a specific schema. Each record can be equivalent to an event. ESB Streaming Integrator can integrate databases into the streaming flow by extracting records in database tables as streaming events. This can be done via change data capture or by polling a database.
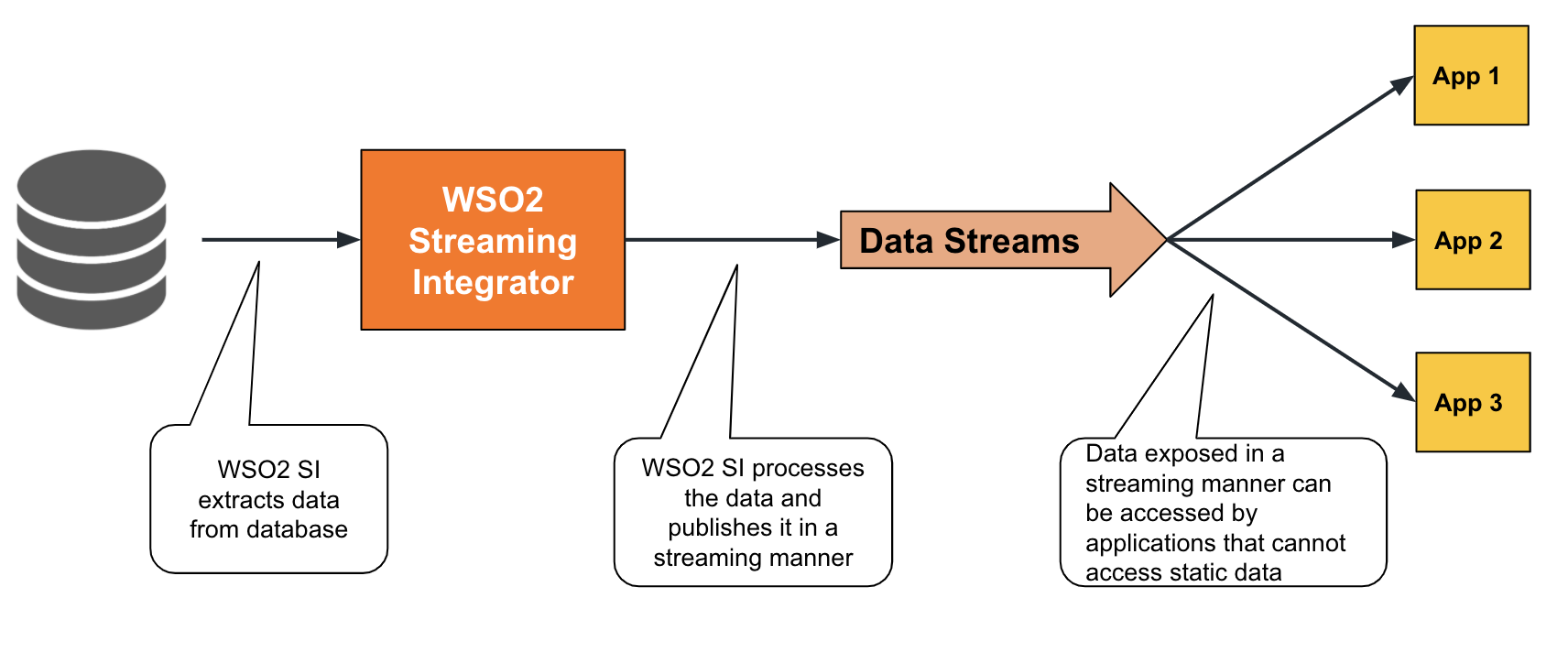
To understand how data is extracted from a database into a streaming flow, consider a scenario where an online booking site automatically save all online bookings of vacation packages in a database. The company wants to monitor the bookings in real-time. Therefore, this data stored in the database needs to be extracted in real time. You can either capture this data as change data or poll the database. The cdc Siddhi extensions can be used for both methods as explained in the following subsections.
Change data capture¶
Change data capture involves extracting any change that takes place in a selected database (i.e., any insert, update or a deletion) in real-time.
To capture change data via the ESB Streaming Integrator Tooling, define an input stream with the appropriate schema to capture the information you require, and then connect a source of the cdc type as shown in the example below.
@source(type = 'cdc',
url = "jdbc:mysql://localhost:3306/tours?useSSL=false",
username = "wso2si",
password = "wso2",
table.name = "OnlineBookingsTable",
operation = "insert",
mode = "listening", jdbc.driver.name = "com.mysql.jdbc.Driver",
@map(type = 'keyvalue'))
define stream OnlineBookingsStream (ref int, timestamp int, name string, package string, people int);mode parameter of the cdc source is set to listening. This mode involves listening to the database for the specified database operation. In this example, the operation parameter is set to insert. Therefore, the source listens to new records inserted into the OnlineBookingsTable table and generates an input event in the OnlineBookingsStream stream for each insert.
If you want to capture updates to the records in the OnlineBookingsTable database table in real time, you can change the value for the operation parameter to update as shown below.
@source(type = 'cdc',
url = "jdbc:mysql://localhost:3306/tours?useSSL=false",
username = "wso2si",
password = "wso2",
table.name = "OnlineBookingsTable",
operation = "update",
mode = "listening",
jdbc.driver.name = "com.mysql.jdbc.Driver",
@map(type = 'keyvalue'))
define stream OnlineBookingsStream (ref int, timestamp int, name string, package string, people int);OnlineBookingsTable database table in real time, you can change the value for the operation parameter to delete as shown below.
@source(type = 'cdc',
url = "jdbc:mysql://localhost:3306/tours?useSSL=false",
username = "wso2si",
password = "wso2",
table.name = "OnlineBookingsTable",
operation = "delete",
mode = "listening",
jdbc.driver.name = "com.mysql.jdbc.Driver",
@map(type = 'keyvalue'))
define stream OnlineBookingsStream (ref int, timestamp int, name string, package string, people int);Polling databases¶
This method involves periodically polling a database table to capture changes in the data. Similar to change data capture, you can define an input stream with the appropriate schema to capture the information you require, and then connect a source of the cdc type as shown in the example below. However, for polling, the value for the mode parameter must be polling
@source(type = 'cdc',
url = 'jdbc:mysql://localhost:3306/tours?useSSL=false',
mode = 'polling',
jdbc.driver.name = 'com.mysql.jdbc.Driver',
polling.column = 'timestamp',
polling.interval = '10',
username = 'wso2si',
password = 'wso2',
table.name = 'OnlineBookingsTable',
@map(type = 'keyvalue' ))
define stream OnlineBookingsStream (ref int, timestamp long, name string, package string, people int);OnlineBookingsTabletable every 10 seconds and captures all inserts and updates to the database table that take place during that time interval. An input event is generated in the OnlineBookingsStream stream for each insert and update.
Tip
- The
pollingmode only captures insert and update operations. Unlike in thelisteningmode, you do not need to specify the operation.
Try out an example¶
Let's try out the example where you want to view the online bookings saved in a database in real time. To do this, follow the steps below:
-
Download and install MySQL.
-
Enable binary logging in the MySQL server. For detailed instructions, see Debezium documentation - Enabling the binlog.
!!! info If you are using MySQL 8.0, use the following query to check the binlog status.
SELECT variable_value as "BINARY LOGGING STATUS (log-bin) ::" FROM performance_schema.global_variables WHERE variable_name='log_bin'; -
Start the MySQL server, create the database and the database table you require as follows:
-
To create a new database, issue the following MySQL command.
CREATE SCHEMA tours; -
Create a new user by executing the following SQL query.
GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'wso2si' IDENTIFIED BY 'wso2';-
Switch to the
toursdatabase and create a new table, by executing the following queries.use tours;CREATE TABLE tours.tours ( ref INT NOT NULL AUTO_INCREMENT, timestamp LONGTEXT NULL, name VARCHAR(45) NULL, package VARCHAR(45) NULL, people INT NULL, PRIMARY KEY (ref)); -
Download the
cdc-mysqlSiddhi extension for Streaming Integrator Tooling. For instructions, see Installing Siddhi Extensions. -
In Streaming Integrator Tooling, open a new file. Copy and paste the following Siddhi application to it.
@App:name("VacationsApp") @App:description("Captures cdc events from MySQL table") @source(type = 'cdc', url = "jdbc:mysql://localhost:3306/tours?useSSL=false", username = "wso2si", password = "wso2", table.name = "OnlineBookingsTable", operation = "insert", mode = "listening", jdbc.driver.name = "com.mysql.jdbc.Driver", @map(type = 'keyvalue')) define stream OnlineBookingsStream (ref int, timestamp long, name string, package string, people int); @sink(type = 'log') define stream LogStream (ref int, timestamp long, name string, package string, people int); @info(name = 'query') from OnlineBookingsStream select * insert into LogStream;Then save the Siddhi application.
This Siddhi application uses acdcsource that extracts events in the change data capturing (i.e., listening) mode and logs the captured records in the console via alogsink. -
Start the Siddhi Application by clicking the play button.

-
To insert a record into the
OnlineBookingsTable, issue the following MySQL command:insert into OnlineBookingsTable(ref,timestamp,name,package,people) values('1',1602506738000,'jem','best of rome',2);The following is logged in the Streaming Integrator Tooling terminal.
INFO {org.wso2.siddhi.core.stream.output.sink.LogSink} - VacationsApp : LogStream : Event{timestamp=1563378804914, data=[1, 1602506738000, jem, best of rome, 2], isExpired=false}
-
Supported databases¶
siddhi-io-cdc source via which the ESB Steaming Integrator extracts database records supports the following database types.
The following is a list of Siddhi extensions that support change data capturing to allow you to extract database records as input events in real time.
| Database Type | Extension Name | Description |
|---|---|---|
| Mongo DB | cdc-mongodb |
Captures change data from Mongo DB databases. |
| MS SQL | cdc-mssql |
Captures change data from MS SQL databases. |
| MySQL | cdc-mysql |
Captures change data from MySQL databases. |
| Oracle | cdc-oracle |
Captures change data from Oracle databases. |
| PostgreSQL | cdc-postgresql |
Captures change data from PostgreSQL databases. |
Supported mappers¶
Mappers determine the format in which the event is received. For information about transforming events by changing the format in which the data is received/published, see Transforming Data.
The mapper available for extracting data from databases is Keyvalue.
File Processing¶
File Processing involves two types of operations related to files:
-
Extracting data from files: This involves extracting the content of file as input data for further processing.
-
Managed file transfer: This involves using statistics of operations carried out for files (e.g., creating, editing, moving, deleting, etc.) as input data for further processing.
e.g., In a sweet factory where the production bots publishes the production statistics in a file after each production run. Extracting the production statistics from the files for further processing can be considered reading files and extracting data. Checking whether a file is generated to indicate a completed production run, and checking whether a file is moved to a different location after its content is processed can be considered as managed file transfer.
To understand how you can perform these file processing activities via the ESB Streaming Integrator, see the subtopics below.
Extracting data from files¶
ESB Streaming Integrator extracts data from files via the File Source. Once it extracts the data, it can publish it in a streaming manner so that other streaming applications that cannot read static data from files.
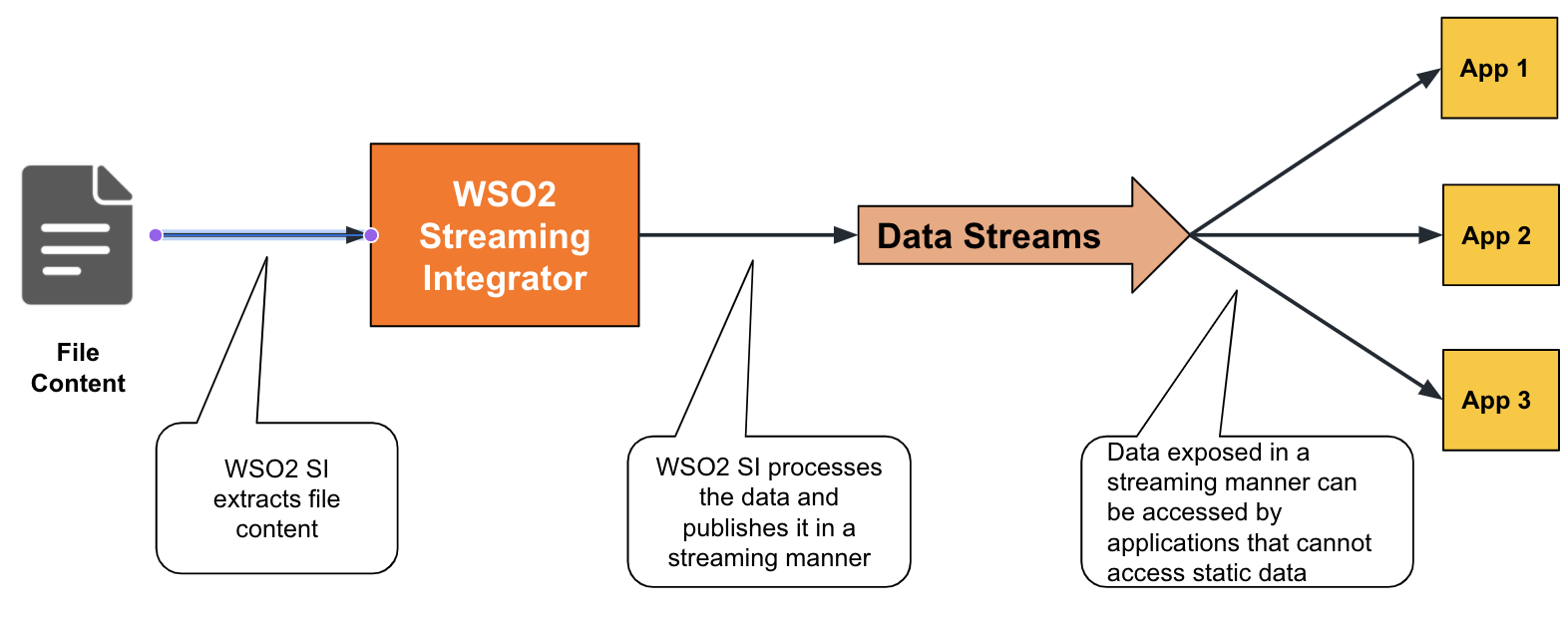
To further understand this, let's try out designing a solution for the Sweet Factory that needs to expose its production statistics in the file generated by production bots in a streaming manner to the production manager so that the statistics can be viewed and analyzed in real time.
Selecting the file(s) to read¶
You can extract data from a single file or from multiple files in a directory. This is specified via the file.uri and dir.uri parameters as shown below:
-
Reading a single file
In the following example, the
file.uriparameter specifies theproductioninserts.csvfile in the/Users/foodirectory as the file from which the source should extract data.@source(type = 'file',file.uri = "file:/Users/foo/productioninserts.csv", @map(type = 'csv')) define stream ProductionStream (name string, amount double); -
Reading multiple files within a directory
In the following example, the
dir.uriparameter specifies the/Users/foo/productionas the directory with the files from which the source extracts information. According to the following configuration, all the files in the directory are read.@source(type = 'file', dir.uri = "file:/Users/foo/production", @map(type = 'csv')) define stream ProductionStream (name string, amount double);If you want the source to read only specific files within the directory, you need to specify the required files via the
file.name.listparameter as shown below.@source(type = 'file', dir.uri = "file:/Users/foo/production", file.name.list = "productioninserts.csv,AssistantFile.csv,ManagerFile.csv", @map(type = 'csv')) define stream ProductionStream (name string, amount double);Selecting the mode in which the file is read¶
The file source can read the selected file(s) in many modes. The available modes are as follows.
| Mode | Description |
|---|---|
TEXT.FULL |
Reads a text file completely in one reading. |
BINARY.FULL |
Reads a binary file completely in one reading. |
BINARY.CHUNKED |
Reads a binary file chunk by chunk. |
LINE |
Reads a text file line by line |
REGEX |
Reads a text file and extracts data using a regex. |
You can specify the required mode via the mode parameter as shown in the example below.
@source(type = 'file',
file.uri = "file:/Users/foo/productioninserts.csv",
mode='LINE'
@map(type = 'csv'))
define stream ProductionStream (name string, amount double);Moving or deleting files after reading/failure¶
If required, you can configure a file source to move or delete the files after they are read or after an attempt to read them has resulted in a failure. In both scenarios, the default action is to delete the file.
e.g., If you want to move the productioninserts.csv file in the previous example after it is read, specify move as the value for action.after.process. Then add the move.after.process to specify the location to which the file should be moved after processing.
@source(type = 'file', file.uri = "file:/Users/foo/productioninserts.csv",
mode = "line",
tailing = "false",
action.after.process = "move",
move.after.process = "file:/Users/processedfiles/productioninserts.csv",
@map(type = 'csv'))
define stream ProductionStream (name string, amount double);productioninserts.csv file from the /Users/foo directory to the /Users/processedfiles after it is processed.
Note that this extract also includes tailing = "false". When tailing is enabled, the source reports any change made to the file immediately. Tailing is available only when the mode is set to LINE or REGEX, and it is enabled for these modes by default. Therefore, if you are using one of these modes and you want to set the action.after.process to move you need to disable tailing.
Supporting Siddhi extension¶
Reading content in files are supported via the file Siddhi extension.
Supporting mappers¶
The following mappers are supported for the File extension.
| Transport | Supporting Siddhi Extension |
|---|---|
csv |
csv |
xml |
xml |
text |
text |
Performing managed file transfers¶
ESB Streaming Integrator supports managed file transfers which involves detecting whether a file is created/modified/removed.
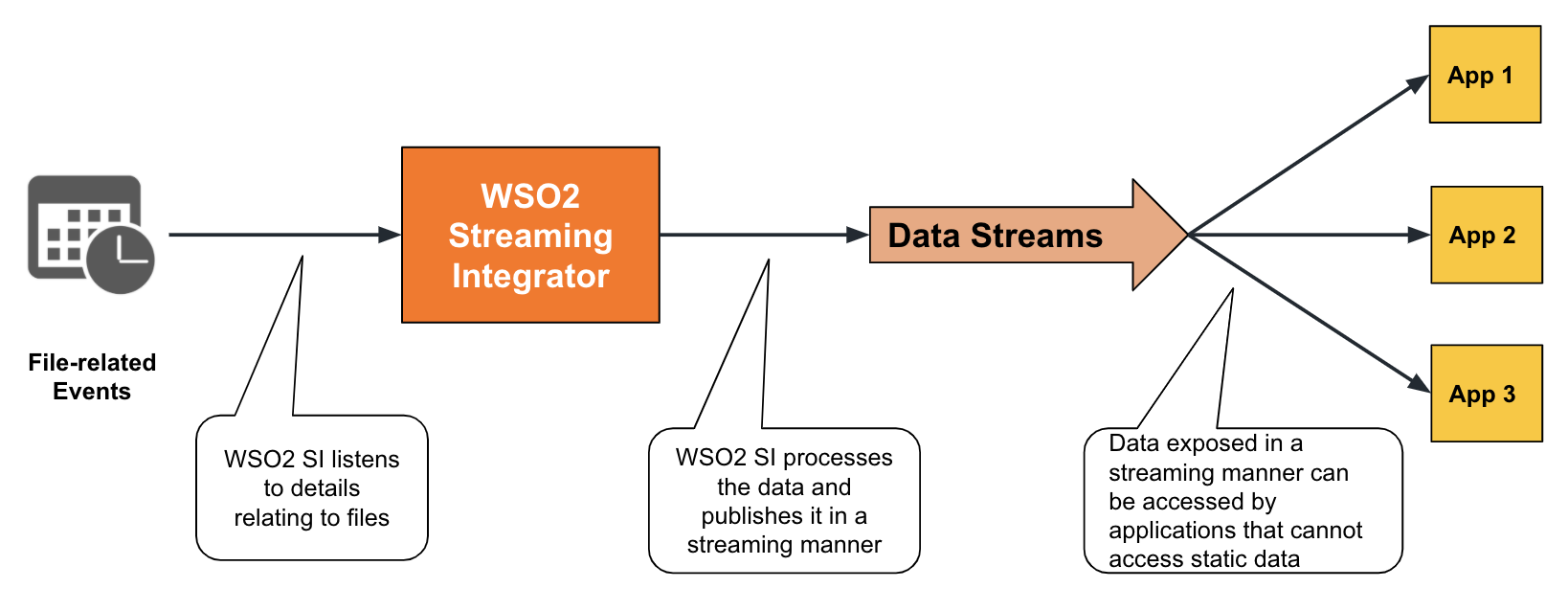
To check whether any file is created, modified or removed in a specific directory, you can configure a source of the fileeventlistener connected to an event stream as follows.
@source(type = 'fileeventlistener',
dir.uri = "file:/Users/foo",
@map(type = 'passThrough'))
define stream FileListenerStream (filepath string, filename string, status string);/Users/foo directory. If any file was created/modified/removed in the directory, an event is generated in the FileListenerStream stream. This event reports the name of the file, the file path, and the status of the file.
If you want to monitor only activities generated for a specific file, you need to specify the names of the files via the file.name.list parameter as shown in the example below.
@source(type = 'fileeventlistener',
dir.uri = "file:/Users/foo",
file.name.list = "productioninserts 18.01.22.csv,materialconsumption.txt",
@map(type = 'passThrough'))
define stream FileListenerStream (filepath string, filename string, status string);FileListenerStream only when the productioninserts 18.01.22.csv and materialconsumption.txt are created, modified, and/or removed.
If you want the directory to be monitored for file events periodically, you can specify the required monitoring interval in milliseconds via the monitoring.interval parameter as shown in the example below.
@source(type = 'fileeventlistener',
dir.uri = "file:/Users/foo",
monitoring.interval = "200",
file.name.list = "productioninserts 18.01.22.csv,materialconsumption.txt",
@map(type = 'passThrough'))
define stream FileListenerStream (filepath string, filename string, status string);/Users/foo directory every 200 milliseconds, and an event is generated in the FileListenerStream for each file transaction that involved creating/modifying/removing a file named productioninserts 18.01.22.csv or materialconsumption.txt.
Supporting Siddhi extension¶
Capturing file events is supported via the fileeventlistener Siddhi extension.
Try out an example¶
To try out reading the content of a file and file events, let's address the requirement of the example mentioned before of a sweet factory that publishes production details in a file.
-
Start and access ESB Streaming Integrator Tooling.
-
Open a new file and add the following Siddhi application.
@App:name('LogFileEventsApp') @App:description('Description of the plan') @source(type = 'fileeventlistener', dir.uri = "file:/Users/production", @map(type = 'passThrough')) define stream FileListenerStream (filepath string, filename string, status string); @sink(type = 'log', @map(type = 'passThrough')) define stream LogFileEventsStream (filepath string, filename string, status string); @info(name = 'Query') from FileListenerStream select * insert into LogFileEventsStream;Tip
You can change the
Users/productiondirectory path to the path of a preferred directory in your machine.Then save the file as
LogFileEventsApp.The above Siddhi Application monitors the
Users/productiondirectory and generates an event in theFileListenerStreamif any file is created/modified/removed in it. -
Start the
LogFileEventsAppSiddhi application you created by clicking on the play icon in the top panel. -
Open a new file in a text editor of your choice, and save it as
productionstats.csvin theUsers/productiondirectory.As a result, the following is logged in the Streaming Integrator Tooling terminal to indicate that the
productionstats.csvis created in theUsers/productiondirectory.INFO {io.siddhi.core.stream.output.sink.LogSink} - LogFileEventsApp : LogFileEventsStream : Event{timestamp=1603105747423, data=[/Users/production/productionstats.csv, productionstats.csv, created], isExpired=false} -
Create and save the following Siddhi application in Streaming Integrator Tooling.
@App:name("FileReadingApp") @source(type = 'file', file.uri = "file:/Users/production/productionstats.csv", mode = "line", tailing = "false", action.after.process = "move", move.after.process = "file:/Users/processedfiles/productionstats.csv", @map(type = 'csv')) define stream ProductionStream (name string, amount double); @sink(type = 'log', @map(type = 'passThrough')) define stream LogStream (name string, amount double); @info(name = 'Query') from ProductionStream select * insert into LogStream;
This Siddhi application reads the content of the /Users/production/productionstats.csv file that you previously created and generates an event per row in the ProductionStream stream. After reading the file, the Siddhi app moves it to the /Users/processedfiles directory.
-
Start the
FileReadingAppSiddhi application. -
Open the
/Users/production/productionstats.csvfile, add the following content to it, and then save the file.
The following is logged in the Streaming Integrator Tooling terminal:Almond cookie,100.0 Baked alaska,20.0-
For the
FileReadingAppSiddhi applicationINFO {io.siddhi.core.stream.output.sink.LogSink} - FileReadingApp : LogStream : Event{timestamp=1603106006720, data=[Almond cookie, 100.0], isExpired=false}INFO {io.siddhi.core.stream.output.sink.LogSink} - FileReadingApp : LogStream : Event{timestamp=1603106006720, data=[Baked alaska, 20.0], isExpired=false}These logs show the content of the
productionstats.csvfile that is read by ESB Streaming Integrator. -
For the
LogFileEventsAppSiddhi applicationINFO {io.siddhi.core.stream.output.sink.LogSink} - LogFileEventsApp : LogFileEventsStream : Event{timestamp=1603106006807, data=[/Users/production/productionstats.csv, productionstats.csv, removed], isExpired=false}This log indicates that the ESB Streaming Integrator has detected that the 'productionstats.csv
file is removed from the/Users/production` directory.
-
Consuming data from cloud storages¶
ESB Streaming Integrator allows you to access data in cloud storages (such as Amazon Web Services - SQS, Amazon Web Services - S3, and Google Cloud Platform) and expose it in a streaming manner to applications that cannot access cloud storages. Cloud-based data sources generally cannot be tailed and therefore, it is challenging to expose changes to the stored data in real time. ESB Streaming Integrator addresses this issue by periodically polling the cloud storage, transferring the changes detected during those polling intervals to a file, and then tailing the file to expose the data in a streaming manner as illustrated in the following diagram.
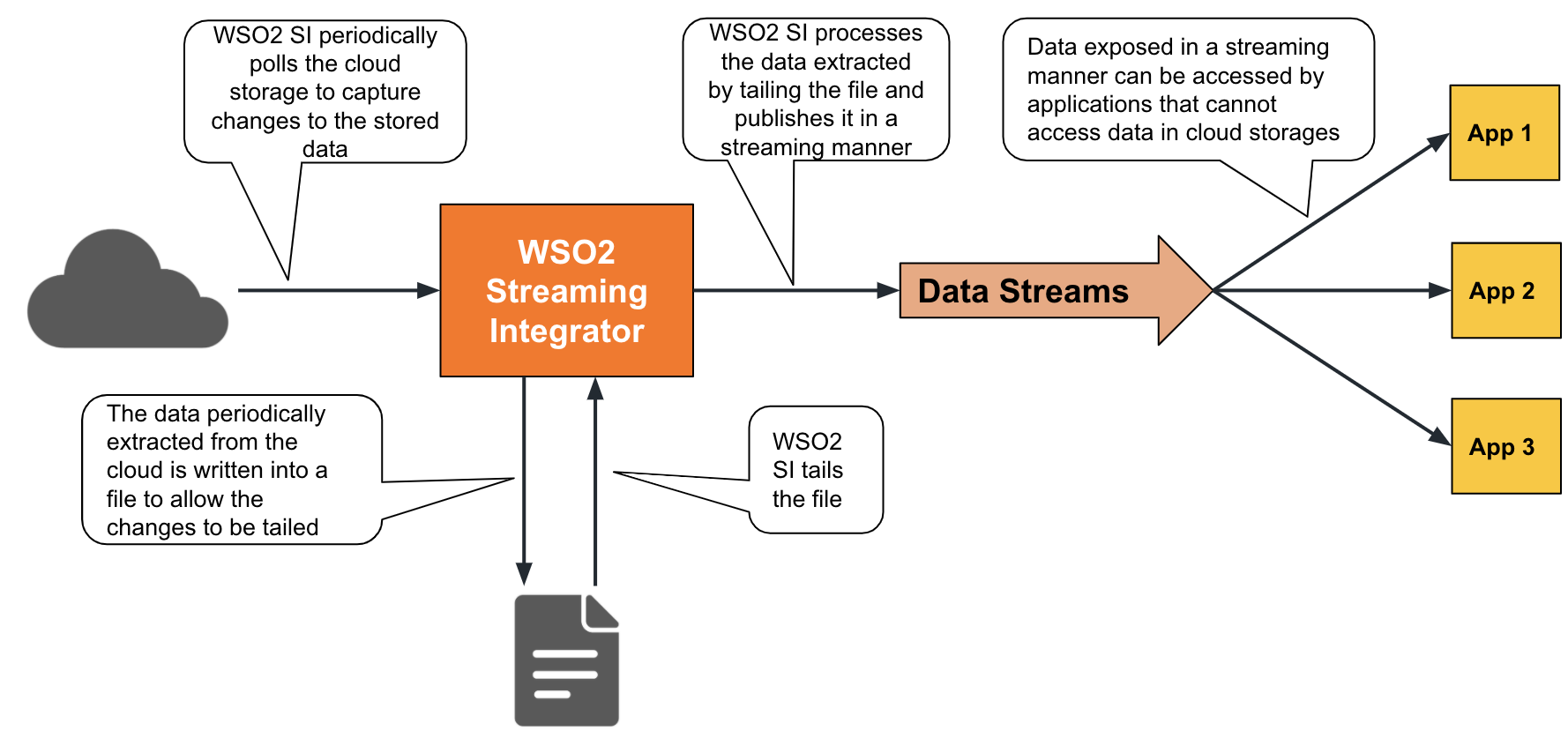
The following is an example where the ESB Streaming Integrator retrieves messages from an SQS queue. A source of the sqstype is used for this purpose where you can provide the URL to the SQS queue that you want to subscribe to, and provide the access key and the secret to access it. the queue is polled periodically (i.e., every 5000 milliseconds). The source generates an event in the InStream stream for each message it retrieves.
@source(type='sqs',
queue='http://aws.sqs.queue.url',
access.key='aws.access.key',
secret.key='aws.secret.key',
region='us-east-2',
polling.interval='5000',
max.number.of.messages='10',
number.of.parallel.consumers='1',
purge.messages='true',
wait.time='2',
visibility.timeout='30',
delete.retry.interval='1000',
max.number.of.delete.retry.attempts='10',
@map(type='xml',enclosing.element="//events",@attributes(symbol='symbol', message_id='trp:MESSAGE_ID') ))
define stream InStream (symbol string, message_id string);To transfer the content of the cloud storage to a file, add another stream with a sink of the file type as shown in the example below.
Tip
To learn more about publishing data to files, see Loading and Writing Data.
@sink(type = 'file',
file.uri = "/Users/messages/messages.csv",
@map(type = 'json'))
define stream ExtractCloudDataStream (symbol string, message_id string);Then write a query as follows to send all the events in the InStream stream to the ExtractCloudDataStream stream so that all the events extracted from the cloud can be transferred to the /Users/messages/messages.csv file.
@info(name = 'MoveCloudContentToFile')
from InStream
select *
insert into ExtractCloudDataStream;@App:name('CloudProcessingApp')
@App:description('Description of the plan')
@source(type = 'sqs', queue = "http://aws.sqs.queue.url", access.key = "aws.access.key", secret.key = "aws.secret.key", region = "us-east-2", polling.interval = "5000", max.number.of.messages = "10", number.of.parallel.consumers = "1", purge.messages = "true", wait.time = "2", visibility.timeout = "30", delete.retry.interval = "1000", max.number.of.delete.retry.attempts = "10",
@map(type = 'xml', enclosing.element = "//events",
@attributes(symbol = "symbol", message_id = "trp:MESSAGE_ID")))
define stream InStream (symbol string, message_id string);
@sink(type = 'file',
file.uri = "/Users/messages/messages.csv",
@map(type = 'json'))
define stream ExtractCloudDataStream (symbol string, message_id string);
@info(name = 'MoveCloudContentToFile')
from InStream
select *
insert into ExtractCloudDataStream;Now you can tail the data that is stored in the cloud by tailing the /Users/messages/messages.csv file. For more information about extracting information from files, see Extracting data from files.
Supported cloud platforms¶
The following is a list of cloud platforms from which you can extract stored data via ESB Streaming Integrator.
| Cloud Platform | Extension |
|---|---|
| AWS SQS | SQS |
| AWS Simple Cloud Storage (S3) | S3 |
| Google Cloud Storage | GCS |
| CosmosDB | CosmosDB |
| Azure Data Lake | azuredatalake |
Supported mappers¶
Mappers determine the format in which the event is received. For information about transforming events by changing the format in which the data is received/published, see Transforming Data.
ESB Streaming Integrator supports the following mappers for the cloud-based storages from which it extracts data.
| Mapper | Supporting Siddhi Extension |
|---|---|
json |
json |
xml |
xml |
text |
text |
avro |
avro |
binary |
binary |
keyvalue |
keyvalue |
csv |
csv |
protobuf |
protobuf |