Performing ETL Operations¶
ETL (Extract Transform Load) is a form of data processing that involves extracting data from one or multiple sources (typically from multiple sources), transforming data to generate the required output, and then loading that output to one or more destinations to make it available for further processing.
The following topics explain how ESB Streaming Integrator performs ETL operations, and how it addresses the modern business requirements relating to ETL operations.
Performing ETL in real time¶
Traditional ETL used batch processing method where the ETL tasks were executed periodically on static data (e.g., database records). Due to this, the required output was also generated periodically and it involved a lot of waiting time. However, modern businesses often carry out a high volume of transactions in real time. This requires the ETL operations also to be executed in real time and to generate the results in real time so that quick decisions can be made based on this output.
ESB Streaming Integrator executes ETL operations on streaming data and generates results in a streaming manner. To understand how this is done, consider a scenario where a sweet factory purchases sugar and flour from two suppliers. Each supplier publishes information about each consignment of raw material it supplies in a file. The events published by the sugar supplier does not include the product name. The flour supplier also supplies goods other than raw material. The head office needs all the purchase records saved in a database. The details of each consignment that needs to be saved as a purchase record includes the transaction number, product name, unit price and the amount.
To maintain a database with purchase records, you can create an ETL application as follows:
@App:name('ManagingStocksApp')
@App:description('Maintains purchase records')
@source(type='file', mode='LINE',
file.uri='file:/Users/foo/SugarSupply.csv',
tailing='true',
@map(type='csv'))
define stream SugarSupplyStream (transNo string, price double, amount double);
@source(type='file', mode='LINE',
file.uri='file:/Users/foo/FlourSupply.csv',
tailing='true',
@map(type='csv'))
define stream FlourSupplyStream (transNo string, name string, price double, amount double);
@primaryKey('transNo')
@index ('name')
@store (type='rdbms', datasource='RAW_MATERIAL_DB')
define table PurchaseRecords(transNo string, name string, price double, amount double);
@info(name = 'CleaningSugarSupplyData')
from SugarSupplyStream
select transNo, "sugar" as name, price, amount
update or insert into PurchaseRecords
on PurchaseRecords.transNo == transNo;
@info(name = 'CleaningFlourSupplyData')
from FlourSupplyStream [name == "flour"]
select *
update or insert into PurchaseRecords
on PurchaseRecords.transNo == transNo;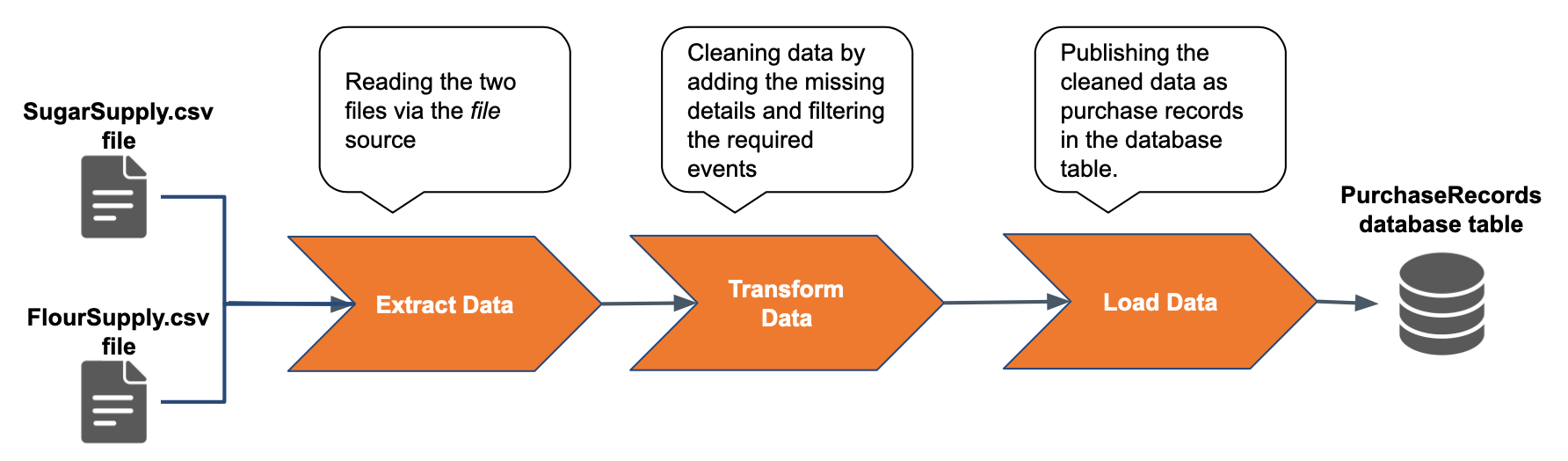
Here, you are extracting the input by tailing the SugarSupply.csv and FlourSupply.csv files in which suppliers publish details of their supplies in real time. This is done via a file source.
To transform the input data, you are performing two cleansing activities. In the first query named CleaningSugarSupplyData, you are introducing a new attribute named name with sugar as the value for all the events received from the sugar supplier via the SugarSupply.csv file. In the second query, you are filtering the events received from the flour supplier to save only details of flour purchases (i.e., because the same supplier also supplies labels).
You are loading the output by performing update or insert operations to insert events from both suppliers into the PurchaseRecords database table after carrying out the data cleansing described above. This enables the cleansed data to be used for further processing.
Integrating heterogeneous data sources¶
In the previous example, you extracted information from two sources of the same type (i.e., files). In real world business scenarios, you often need to extract data from multiple sources of different types.
To understand how this requirement can be addressed via the ESB Streaming Integrator, let's try out consuming events from both a file and a database at the same time.
Assume that the Head Office of the Sweet Factory also maintains a record of the current stock of each material in a database table named StockRecords. To keep the stock updated, each purchase of a raw material needs to be added to the existing stock, and each dispatch to the factory needs to be deducted from the existing stock. The material dispatches are recorded in a file. To achieve this, you need to create an ETL flow as shown in the below diagram.
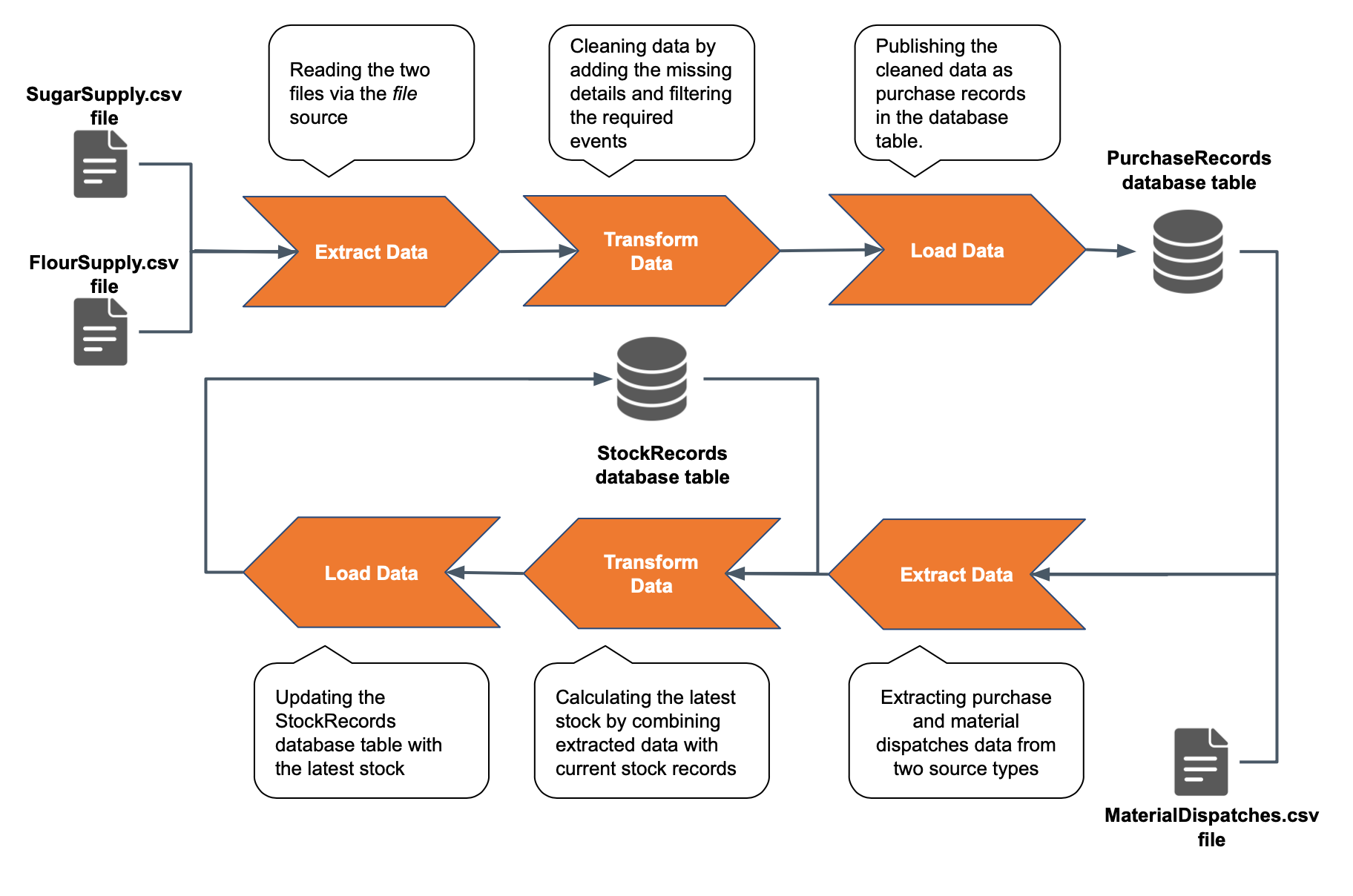
ESB Stream Processor needs to extract events from that file and the PurchaseRecords database table simultaneously to update the stock records. To do this, you can define two input streams and connect then to the relevant sources as follows:
@source(type = 'cdc', url = 'jdbc:mysql://localhost:3306/PurchaseRecords', username = 'root', password = 'root', table.name = 'PurchaseRecords', operation = 'insert',
@map(type = 'keyvalue'))
define stream PurchasesStream (name string, amount double);
@source(type='file', mode='LINE',
file.uri='file:/Users/foo/MaterialDispatches.xml',
tailing='true',
@map(type='xml'))
define stream MaterialDispatchesStream (name string, amount double); The PurchasesStream uses a cdc source to extract all the insert records of the PurchaseRecords database table in real time. At the same time, the MaterialDispatches stream extracts all the material dispatches saved in the MaterialDispatches.xml file in realtime by tailing it. Here, you are receiving data via heterogeneous sources as well as in heterogeneous formats (i.e., in key value format from the database and in XML format from the file).
To maintain stock records, you can define a table as follows:
@primaryKey('name')
@store (type='rdbms', datasource='STOCKS_DB')
define table StockRecords(name string, amount double);Assuming that the stock records are updated per minute, the amount by which the stocks need to be updated during a minute is a difference between the total purchases and the total dispatched that took place during that minute. You can calculate this difference by adding another query as follows:
@info(name = 'CalculateStockUpdate')
from PurchasesStream#window.timeBatch(1 min) as p
join MaterialDispatchesStream#window.timeBatch(1 min) as d
on p.name == d.name
select p.name as name, sum(p.amount) - sum(d.amount) as amount
group by p.name
insert into StockUpdatesStream;Here, we are joining the PurchaseStream stream and the MaterialDispatchesStream stream to calculate the difference. This is a transform operation that you are performing on the data you extracted from the two heterogeneous sources. To learn more about performing joins, see Siddhi Query Guide - Join.
Now you can add the stock update to the StockRecords table as follows.
@info(name = 'UpdateStock')
from StockUpdatesStream#window.timeBatch(1 min) as s
join StockRecords#window.timeBatch(1 min) as r
on s.name == r.name
select s.name as name, s.amount + r.amount as amount
group by s.name
update or insert into StockRecords
on StockRecords.name == name;The above query performs a join between the StockUpdatesStream stream and the StockRecords table, and adds the stock update calculated to the existing amount in the StockRecords table. Then to load the final output, the query performs an update or insert into operation to the Stock Records table. This means, if the table already has a record with a same value for the name field as the latest output event generated in the StockUpdatesStream stream, the output event overwrites the record in the table. If no such matching record is found, the output event is inserted as a new record.
The queries above updates the ETL flow as shown in the diagram
Once you add all the new Siddhi queries and configurations introduced in this section to the original ManagingStocksApp Siddi application, it looks as follows:
@App:name('ManagingStocksApp')
@App:description('Maintains the latest stock amounts')
@source(type='file', mode='LINE',
file.uri='file:/Users/foo/SugarSupply.csv',
tailing='true',
@map(type='csv'))
define stream SugarSupplyStream (transNo string, price double, amount double);
@source(type='file', mode='LINE',
file.uri='file:/Users/foo/FlourSupply.csv',
tailing='true',
@map(type='csv'))
define stream FlourSupplyStream (transNo string, name string, price double, amount double);
@source(type = 'cdc', url = 'jdbc:mysql://localhost:3306/RAW_MATERIAL_DB', username = 'root', password = 'root', table.name = 'PurchaseRecords', operation = 'insert',
@map(type = 'keyvalue'))
define stream PurchasesStream (name string, amount double);
@source(type='file', mode='LINE',
file.uri='file:/Users/foo/MaterialDispatches.csv',
tailing='true',
@map(type='csv'))
define stream MaterialDispatchesStream (name string, amount double);
@primaryKey('transNo')
@index ('name')
@store (type='rdbms', datasource='RAW_MATERIAL_DB')
define table PurchaseRecords(transNo string, name string, price double, amount double);
@primaryKey('name')
@store (type='rdbms', datasource='STOCKS_DB')
define table StockRecords(name string, amount double);
@info(name = 'CleaningSugarSupplyData')
from SugarSupplyStream
select transNo, "sugar" as name, price, amount
update or insert into PurchaseRecords
on PurchaseRecords.transNo == transNo;
@info(name = 'CleaningFlourSupplyData')
from FlourSupplyStream [name == "flour"]
select *
update or insert into PurchaseRecords
on PurchaseRecords.transNo == transNo;
@info(name = 'CalculateStockUpdate')
from PurchasesStream#window.timeBatch(1 min) as p
join MaterialDispatchesStream#window.timeBatch(1 min) as d
on p.name == d.name
select p.name as name, sum(p.amount) - sum(d.amount) as amount
group by p.name
insert into StockUpdatesStream;
@info(name = 'UpdateStock')
from StockUpdatesStream#window.timeBatch(1 min) as s
join StockRecords#window.timeBatch(1 min) as r
on s.name == r.name
select s.name as name, s.amount + r.amount as amount
group by s.name
update or insert into StockRecords
on StockRecords.name == name;
Scalability¶
When there are rapid changes and growths in business, it is necessary to scale ETL applications in an agile manner to support it. ESB Streaming Integrator supports the need for scalability via the Siddhi logic.
This can be observed in the previous examples where the ManagingStocksApp Siddhi application which only captured purchase records in the Performing ETL in real time section and with only two files and one database table (SugarSupply.csv file, FlourSupply.csv file and PurchaseRecords database table) in the ETL flow was scaled to perform stock updates by incorporating another file and a database (i.e., MaterialDispatches.csv file and StockRecords database table) to the ETL flow.
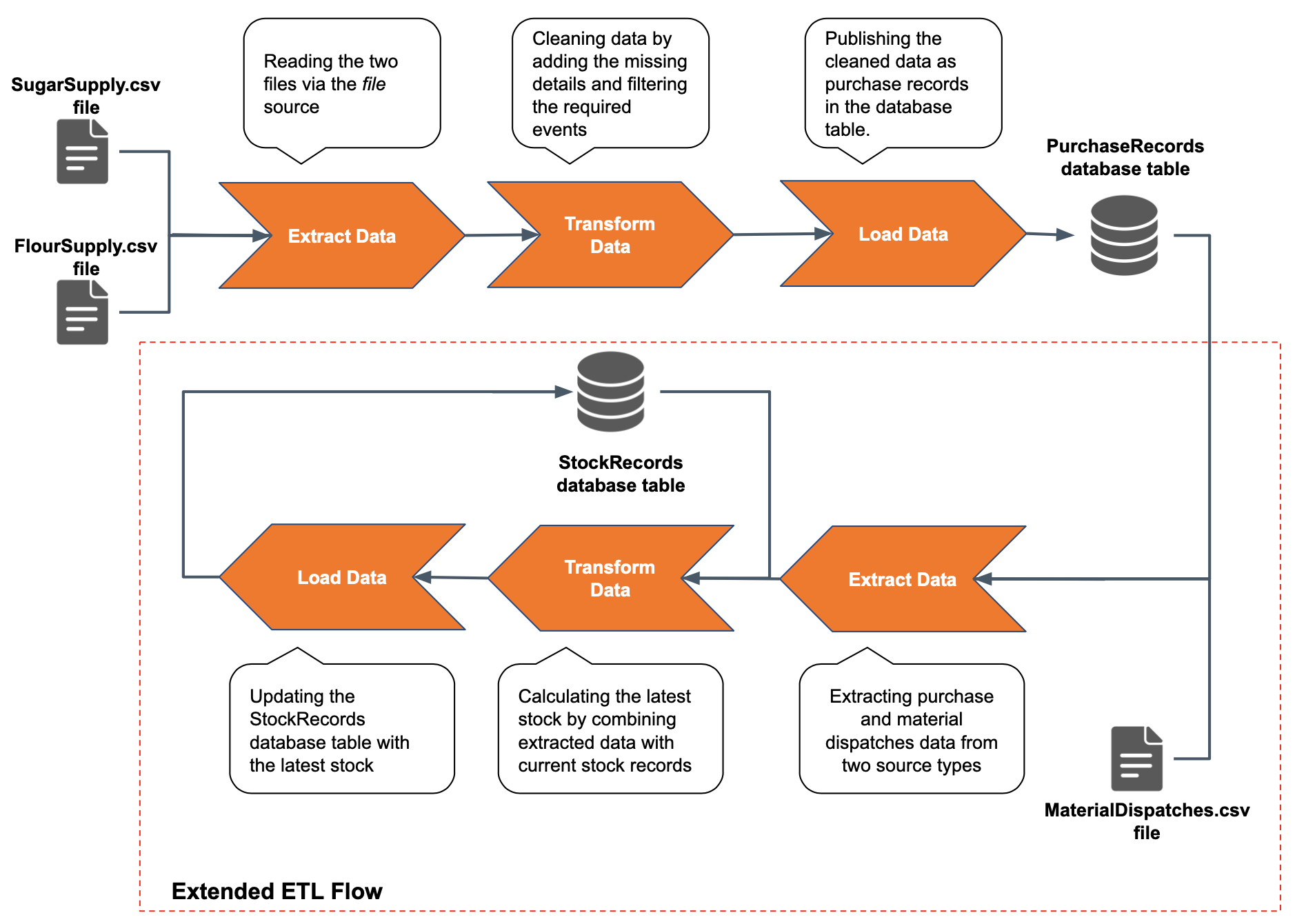
When you extended the ETL flow to perform stock updates, it involved adding more ETL tasks to the flow. You can also scale your ETL applications without adding more ETL tasks. This is done by adding only more sources to extract data for the existing tasks or adding more destinations for the existing tasks to load the output. For example, if the Sweet Factory starts purchasing another ingredient (e.g., honey), you can define another stream to consume from a new source (e.g., a new file named `HoneySupply.xml) as follows:
@source(type='file', mode='LINE',
file.uri='file:/Users/foo/HoneySupply.xml',
tailing='true',
@map(type='xml'))
define stream HoneySupplyStream (transNo string, name string, price double, amount double);Then you can update the existing PurchaseRecords table with information about the purchases of the new material as shown below.
@info(name = 'RecordingHoneySupplyData')
from FlourSupplyStream
select *
update or insert into PurchaseRecords
on PurchaseRecords.transNo == transNo;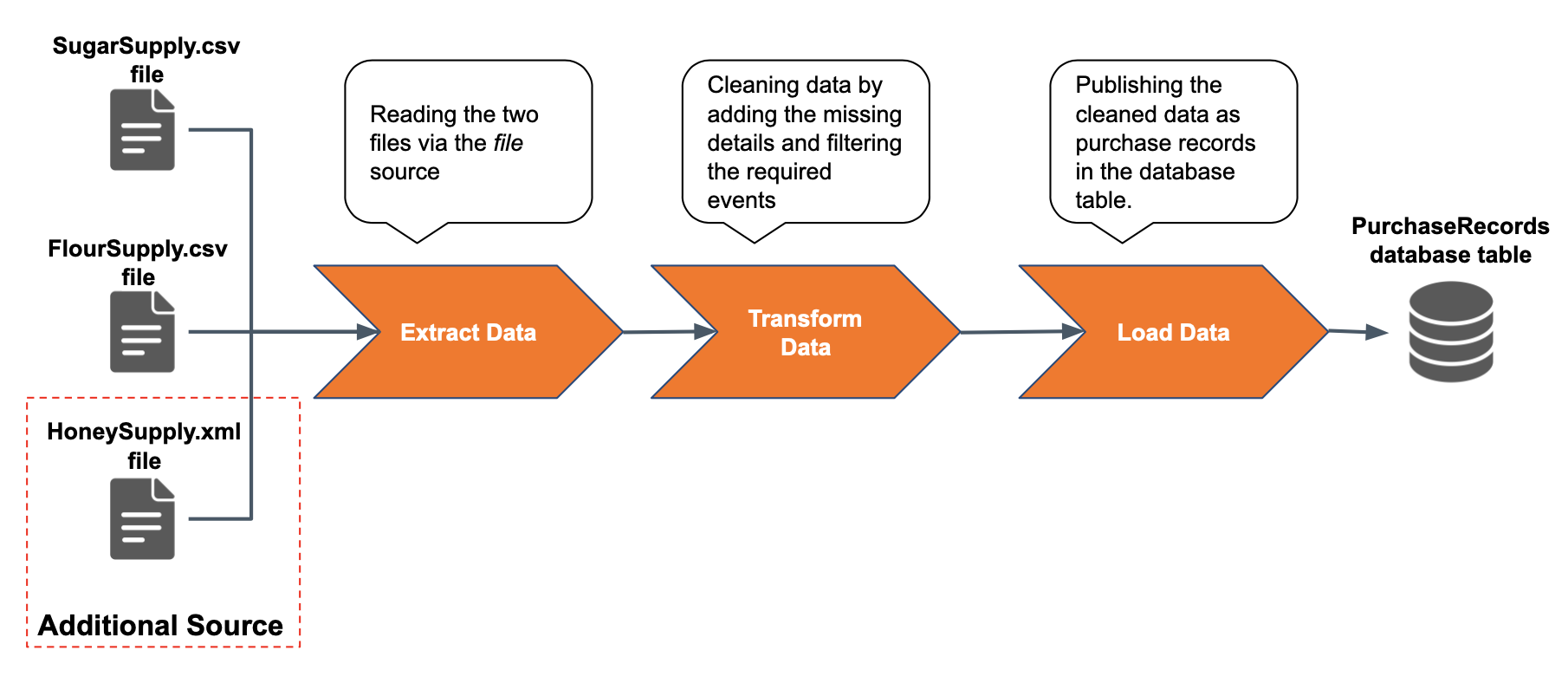
Tip
As you scale your ETL operations, you may have all the related queries in a single application or create multiple Siddhi applications that function as components of the same ETL flow.
Multiple platforms for ETL application design¶
ESB Streaming Integrator provides the Source View, Design View and the Wizard View for application design. For more information, see Streaming Integrator Tooling Overview.
Out of these three views, the Wizard View is dedicated for designing ETL applications without writing many Siddhi queries. This platform mainly caters for application designers who prefer to use Siddhi constructs without writing code. Therefore, it guides you to write multiple simple Siddhi applications that contribute to the same ETL flow instead of heavy applications embodying multiple components of the ETL flow. A single Siddhi application designed using the ETL wizard can only incorporate one source and one destination to the ETL flow.
To learn how to design an ETL application via the Wizard view, see the Creating an ETL Application via SI Tooling tutorial.
Visualizing ETL Performance Statistics¶
ESB Streaming Integrator provides nine pre-configured dashboards to visualize the overall ETLS statistics for your Streaming Integrator deployment, as well as the ETL statistics per Siddhi application and per ETL-related Siddhi extension type (i.e., CDC statistics, file statistics and RDBMS statistics).
You can set up the pre-configured dashboards in Grafana. For instructions to set up these dashboards and visualize your ETL statistics, see Monitoring ETL Statistics with Grafana.
Processing high volumes of data at high speed¶
In real world business scenarios, many businesses carry out about thousands of online transactions per second. This requires an ETL application performing in real time to handle a high volume of data in high speed.
According to the latest performance statistics of the Streaming Integrator, it can process 29,000 transactions per second when performing ETL tasks. For more information about performance statistics, see the following:
- Performance Analysis Results - Performing ETL Tasks
- Streaming ETL with ESB Streaming Integrator article