Active-Active Deployment¶
The recommended deployment for ESB Streaming Integrator (SI) is the Minimum HA Deployment. However, that deployment pattern involves using only two nodes and it is not scalable beyond that. If you want to configure ESB SI as a scalable deployment, you can use the Active-Active deployment pattern. This section provides an overview of the Active-Active deployment pattern and instructions to configure it.
Overview¶
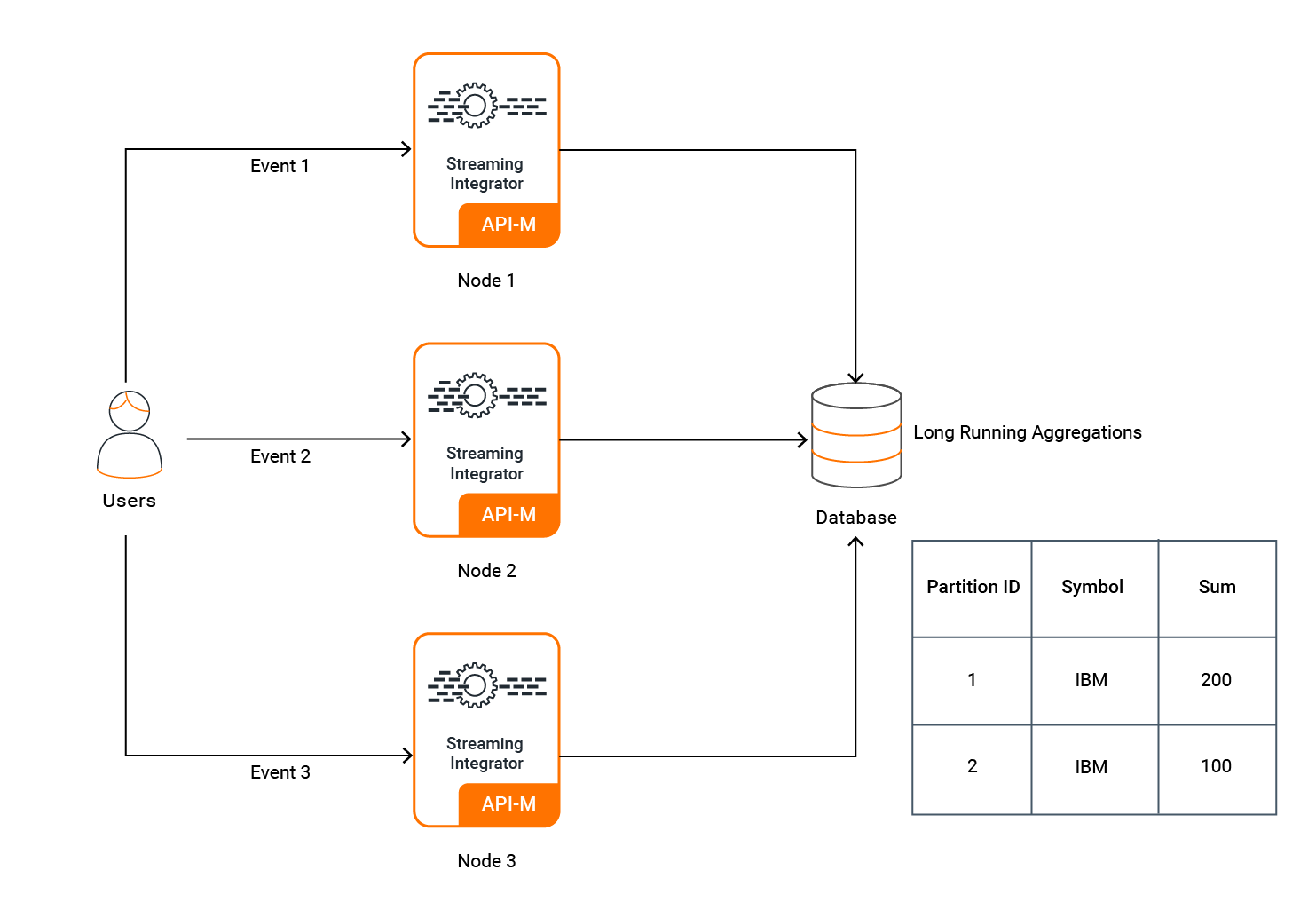
The above diagram represents a deployment where you are not limited to two nodes. You can scale the event processing horizontally by adding more SI nodes to the deployment. In this deployment, it is recommended to configure the client application to publish events to multiple SI nodes in a Round Robin manner to ensure better fault tolerance. The publishing of events can be carried out by one or more clients.
In order to perform aggregations in a distributed manner and achieve the scalability, this setup uses distributed aggregations.
Distributed aggregations partially process aggregations in different nodes. This allows you to assign one node to process only a part of an aggregation (regional scaling, etc.). In order to do this all the aggregations must have a physical database and must be linked to the same database.
Partitioning aggregations can be enabled at aggregation level and also at a global level. To enable it at the global level, add the following section with the
@PartitionById annotation set to true in the <SI_HOME>/conf/server/deployment.yaml file.
siddhi:
properties:
partitionById: true
shardId: wso2-siIf you want to enable for a specific aggregation then the @PartitionById annotation must be added before the aggregation definition as shown in the example below.
e.g., To understand how an active-active cluster processes aggregations when aggregations are partitioned and assigned to different nodes, consider the following Siddhi query. To learn more about Siddhi queries, see Siddhi Query Guide.
define stream TradeStream (symbol string, price double, quantity long, ;timestamp long);
@store(type='rdbms',jdbc.url="jdbc:mysql://localhost:3306/TestDB", username="root", password="root" , jdbc.driver.name="com.mysql.jdbc.Driver")
@PartitionById(enable='true')
define aggregation TradeAggregation
from TradeStream
select symbol, avg(price) as avgPrice, sum(quantity) as total
group by symbol
aggregate by timestamp every sec ... yearThis query captures the information relating to a trade. Each transaction represents an event, and the information captured includes the symbol of the product,
the price at which it is sold, the quantity sold during the transaction, and the timestamp of the transaction. Each node stores this information in the TEST_DB
data store defined in the <SI_WORKER_HOME>/conf/server/deployment.yaml file.
Now let's assume that the following input events were generated for the two nodes during a specific hour.
Node 1
| Event | symbol | price | quantity |
|---|---|---|---|
| 1 | wso2 |
100 |
10 |
| 2 | wso2 |
100 |
20 |
Node 2
| Event | symbol | price | quantity |
|---|---|---|---|
| 1 | wso2 |
100 |
10 |
| 2 | wso2 |
100 |
30 |
Here, node 1 calculates an hourly total of 30, and node 2 calculates an hourly total of 40. When you retrieve the total for this hour via a retrieval query, the result is 70.
You can find the steps to enable aggregation partitioning within the next subsection.
Configuring an active-active cluster¶
To configure the Streaming Integrator nodes and deploy them as an active-active cluster, edit the <SI_HOME>/conf/server/deployment.yaml file as follows:
Before you begin:
- Download two binary packs of the ESB Streaming Integrator.
- Set up a working RDBMS instance to be used by the ESB Streaming Integrator cluster.
-
For each node, enter a unique ID for the
idproperty under thewso2.carbonsection. This is used to identify each node within a cluster. For example, you can add IDs as shown below.-
For node 1:
wso2.carbon: id: wso2-si-1 -
For node 2:
wso2.carbon: id: wso2-si-2
-
-
Enable partitioning aggregations for each node, and assign a unique shard ID for each node. To do this, set the
partitionByIdandshardIdparameters as Siddhi properties as shown below.Info
Assigning shard IDs to nodes allows the system to identify each unique node when assigning parts of the aggregation. If the shard IDs are not assigned, system uses the unique node IDs (defined in step 1) for this purpose.
-
For node 1:
siddhi: properties: partitionById: true shardId: wso2-si-1 -
For node 2:
siddhi: properties: partitionById: true shardId: wso2-si-2
Tip
- To maintain data consistency, do not change the shard IDs after the first configuration.
- When you enable the aggregation partitioning feature, a new column ID named
SHARD_IDis introduced to the aggregation tables. Therefore, you need to do one of the following options after enabling this feature to avoid errors occuring due to the differences in the table schema.- Delete all the aggregation tables for
SECONDS,MINUTES,HOURS,DAYS,MONTHS,YEARS. - Edit the aggregation tables by adding a new column named
SHARD_ID, and add that to the existing primary key list of the table..
- Delete all the aggregation tables for
-
-
Configure a database, and then update the default configuration for the
TEST_DBdata source with parameter values suitable for your requirements.
Warning
As explained in above the events are processed in multiple active nodes. Even though this is usually a stateful operation, you can overcome the node-dependent calculations via distributed aggregation. This allows ESB SI to execute scripts that depend on incremental distributed aggregation.
However, an active-active deployment can affect alerts because alerts also depend on some in-memory stateful operations such as windows. Due to this, alerts can be generated based on the events received by specific node. Thus the alerts are node-dependent, and you need to disable them to run scripts with distributed incremental aggregation.